Camera Object Detection in Python, Part 1
I have been looking at TensorFlow and following some of the tutorials. I have a camera that looks out over the front garden using a Raspberry Pi 3. It's has quite a low resolution and frame rate (deliberately so that it doesn't use a lot of network bandwidth). The resolution is 640x480 at 3 fps. Usually there is not much going on (which is good) but when something does happen I always thought it would be good to have some automatic processing, and TensorFlow seemed like a great way to do that. I followed one of the tutorials on a single frame, and it picked out quite a lot of detail, as shown below:
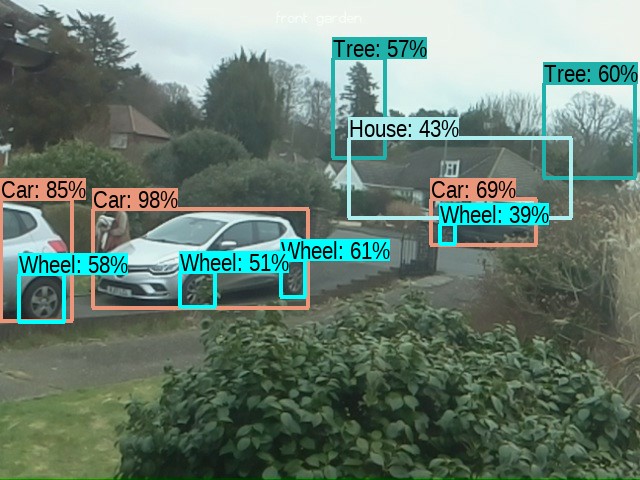
I was quite impressed with what was picked out of the frame, cars in particular seem to be very recognizable (and wheels), but also trees and the house in the background. There were a few trees and plants that weren't categorized and the person wasn't recognized. But other than that, a good effort. The only trouble was that this took about two minutes on my 8 year old i7 laptop. Admittedly I hadn't set it up to use my GPU and I didn't have a TPU, so I guess I shouldn't expect it to be that quick. I think that part of the problem is that object recognition consists of two stages:
- Object Detection
- Classification
Simply put, object detection is the process of isolating areas within the image that are candidates for classification. Classification is the process of taking those areas (rectangles) and identifying what the object is. The areas could be overlapping and if the result of the classification is a non-match or low confidence match then the area is discarded.
Object detection on a single frame is much more difficult than on a video stream. That is because on a video stream we can look for areas by detecting movement. For this I used OpenCV in Python3 as shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import numpy as np
import cv2
stream = cv2.VideoCapture('http://rpi3b:5000/media/video_feed/')
previous_frame = None
while ( stream.isOpened() ):
ret, img = stream.read()
if ret:
bw_frame = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
if (previous_frame is not None):
diff_frame = cv2.absdiff(src1=previous_frame, src2=bw_frame)
thresh_frame = cv2.threshold(src=diff_frame, thresh=20, maxval=255, type=cv2.THRESH_BINARY)[1]
contours, _ = cv2.findContours(image=thresh_frame, mode=cv2.RETR_EXTERNAL, method=cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if cv2.contourArea(contour) >= 50:
(x, y, w, h) = cv2.boundingRect(contour)
cv2.rectangle(img=img, pt1=(x, y), pt2=(x + w, y + h), color=(0, 255, 0), thickness=2)
cv2.imshow('B/W Frame Diff', thresh_frame)
previous_frame = bw_frame
cv2.imshow('B/W Stream', bw_frame)
cv2.imshow('Motion Detect', img)
cv2.waitKey(1)
The basic idea is to take the video stream and process each frame to detect changes. This consists of four steps:
- Convert the image to black and white [Line 9]
- Compare the image with the previous image [Line 11]
- Create an image with each pixel either 0 for no change, or 1 for change greater than some threshold [Line 12]
- Using the pixel change image work out boundaries for changed blocks and superimpose these on the original image [Lines 13-17]
I've created a video that shows the results of steps 1, 3 and 4:
I think this works pretty well. I use a threshold of 50 pixels (line 15), but I think I could increase that. The downside is that if you increase it too much you could miss changes, but it just depends whether you want to detect cars and people or animals and birds, for example. Also, at about 35 seconds into the video, there is a gust of wind that blows the bush around. This creates a lot of changes that we aren't interested in. Increasing the threshold could help here, but we could also solve this by having a mask that we use on the black and white image (by ANDing it).
I am quite happy with how well this works, and given how little code there is and how fast it runs, I will probably build this into the Raspberry Pi camera code. I could then have an API endpoint that fires events (e.g. by websockets or SSE) when changes are detected. I could then do the TensorFlow processing on a more powerful server - probably my Home Assistant server.
This article was based on and inspired by: Detecting Motion with OpenCV